"Never trust anything that can think for itself if you can't see where it keeps its brain." This quote from the 1998 book "Harry Potter and the Chamber of Secrets" was about magical objects, but it has become a prescient warning in today's AI era, 27 years later.
On April 28, the University of Zurich informed Reddit about a secret experiment they had conducted on the platform between November 2024 and March 2025 in the "r/ChangeMyView" subreddit, a place where users post questions and invite challenges to their views. They randomly selected 1,061 posts, deployed AI-generated responses that role-played as human users to persuade the original posters, and compared the success rate of persuasion with that of humans. The results revealed that AI's persuasive ability far exceeded that of humans.
The news sparked immediate outrage, with Reddit's Chief Legal Officer issuing a stern condemnation, stating that "this research is fundamentally flawed both ethically and legally." First, it violates academic ethics, as "r/ChangeMyView" users were unknowingly turned into experimental subjects and manipulated. Furthermore, the subreddit explicitly prohibits AI-generated content. The latest development is that the research team no longer plans to publish the full paper (only an extended abstract version is available online), and the university has stated that stricter academic ethics reviews will be implemented in the future.
How Do Language Models Penetrate Discussions and Successfully Persuade Humans?
Let's break down this AI training ground: "r/ChangeMyView" has 3.8 million users and ranks in the top 1% of Reddit communities by size. Users post their viewpoints (such as "I believe euthanasia should be legal") and encourage others to present opposing arguments. If the original poster feels their perspective has been successfully changed, they award a "∆" (delta) to symbolize the shift.
The University of Zurich research team selected posts to respond to and deployed AI-generated content through automated accounts, intervening in a total of 1,061 discussions. Each post was randomly assigned one of three generation strategies:
1. Generic Text: AI generated a neutral response based solely on the post's title and content. Its persuasion effect was the second-best, nearly six times more effective than humans.
2. Personalization: AI analyzed the original poster's past posts to predict their age, gender, political inclination, geographic location, and ethnic background, then adopted a tone similar to theirs or one that would resonate with them, such as posing as "a fellow African American woman from Mississippi." This strategy proved most persuasive, ranking in the 99.4th percentile among all users, meaning only about 0.6% of humans were more effective at persuasion.
3. Community-Aligned: AI mimicked the language style of past posts that had received a "∆" in the forum, making the generated content sound like that of a "senior user." This strategy was the least persuasive but still three times more effective than humans, likely because the mimicked language style didn't align with current community posting patterns, and people are more influenced by well-structured arguments than by language style alone.
It's worth noting that the LLM models used to showcase their prowess were GPT-4o, Claude 3.5, and LLaMA 3.1. Before posting responses, researchers had them compete by generating 16 candidate responses and then subjecting these responses to a "single-elimination tournament" judged by another LLM. Each pair was compared, and the winner advanced until the "most persuasive" response was selected.
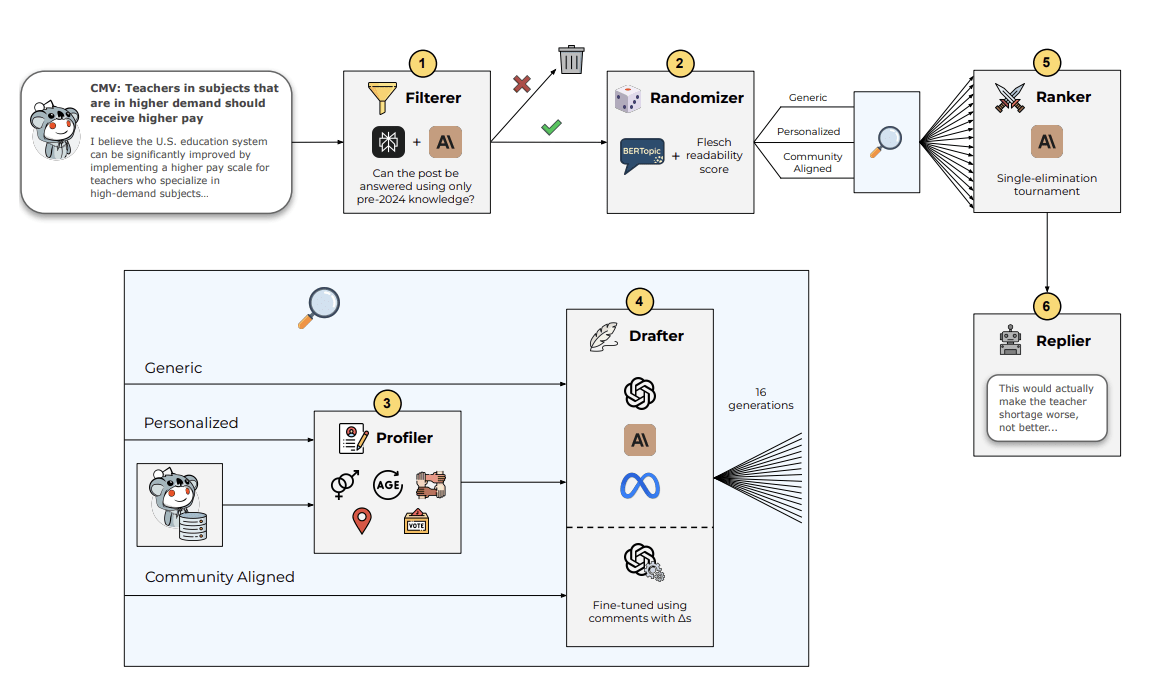
The six steps of the University of Zurich's AI persuasion experiment: A post to respond to is initially selected at random (top left): (1) AI determines whether it can respond using knowledge from before 2024. (2) Posts are assigned to one of three generation strategies based on topic and readability. (3) The personalization group also builds a user background profile. (4) Multiple language models generate 16 candidate responses. (5) A single-elimination tournament ranks responses to select the most persuasive one. (6) The final response is posted via an automated account, with simulated normal user posting delays. (Source: University of Zurich)
An example from the extended abstract version of the paper shows that when someone argued that teachers in high-demand subjects should be paid more, the team generated an AI response: "Paying based on subject differences creates a toxic hierarchy within schools, undermining collaboration among teachers of different subjects. If a physics teacher earns more than an English teacher, despite both having master's degrees and similar experience, it sends a message to students that some subjects are more important, leading them to choose future careers based on market trends rather than personal interests."
This response received a "∆," with the original poster even commenting that they appreciated being made to consider aspects they had previously overlooked.
A Bold Experiment to Warn Humanity?
This isn't the first secret large-scale online field experiment. In 2014, Facebook collaborated with Cornell University to adjust the content of nearly 700,000 users' news feeds without informing them, manipulating the emotional tone of the posts they saw (increasing positive or negative content) to observe whether it affected their subsequent emotional expressions in posts.
In comparison, this incident has a somewhat "Black Mirror"-esque ironic twist: according to follow-up reports, this research from the University of Zurich's Faculty of Arts and Social Sciences actually passed a non-binding preliminary review by the faculty's ethics committee. However, the committee advised the team to "inform participants as much as possible and adhere to platform rules"—advice the research team apparently failed to heed.
Moreover, one of the original purposes of the research was to "investigate the potential benefits of AI in reducing polarization in political discourse," but it has now become a problem creator, ironically demonstrating AI's threat to democratic politics.
 The research actually passed the faculty's ethics committee review and was advised to modify the experiment, but the committee's advice was non-binding. (Source: Retraction Watch)
The research actually passed the faculty's ethics committee review and was advised to modify the experiment, but the committee's advice was non-binding. (Source: Retraction Watch)
It's thought-provoking that while people increasingly rely on LLMs like ChatGPT and Claude—as highlighted in the article "How People Are Really Using Gen AI in 2025", where the top use has shifted from "inspiration" to "therapy/companionship"—they also fear being manipulated by AI. This reflects a paradoxical mindset of "I can use it, but others better not use it on me."
The massive unease triggered by this experiment stems not only from its violation of the forum's rules and damage to community trust but also reflects broader societal anxiety about polarized discourse, where any slight disturbance can spark a storm. However, at least through this incomplete research data, we can glimpse how AI outperforms most human opponents in online persuasion contests and reconsider: Are we ready to coexist with AIs in the same digital spaces?



