Humanity’s Last Exam: AI Benchmarks and Homo Sapiens' Fate

Artificial Intelligence
3-minute read
What sets humans apart from other animals? This question has always been thought-provoking. From the naming of our species, we often hear about "Homo habilis," which hints at our ability to make and use tools, showcasing human intelligence. "Homo erectus" suggests that walking upright freed our hands, implying efficiency. As for the only surviving member of the genus Homo, "Homo sapiens," it highlights our pride in our intelligence, emphasizing our unique cognitive and abstract thinking abilities.
But all of this began to shift with the advent of computers. People believe that one day, AI will surpass human intelligence. Think about the Turing Test from 1950 and today's large language models and chatbots. Who can confidently conduct the "blind test" and distinguish between AI and real people?
Thus, various benchmarks designed for AI models have become today's most objective indicators of AI capabilities. This brings us to what I want to discuss today—"Humanity's Last Exam."
How Tough is "Humanity's Last Exam"?
When I first heard about "Humanity's Last Exam," I was quite surprised by its straightforward name and sci-fi vibes.
"Humanity's Last Exam," as the name suggests, was created because most benchmarks for large language models have been cracked, with scores above 90%. To keep up with the rapid iteration of AI models, the nonprofit Center for AI Safety, dedicated to reducing AI risks, teamed up with Scale AI, a startup that evaluates and builds AI systems for businesses and governments. They brought together experts from over 50 countries, 500 universities, and academic institutions, with around 1,000 professors and researchers to design this interdisciplinary "Humanity's Last Exam."
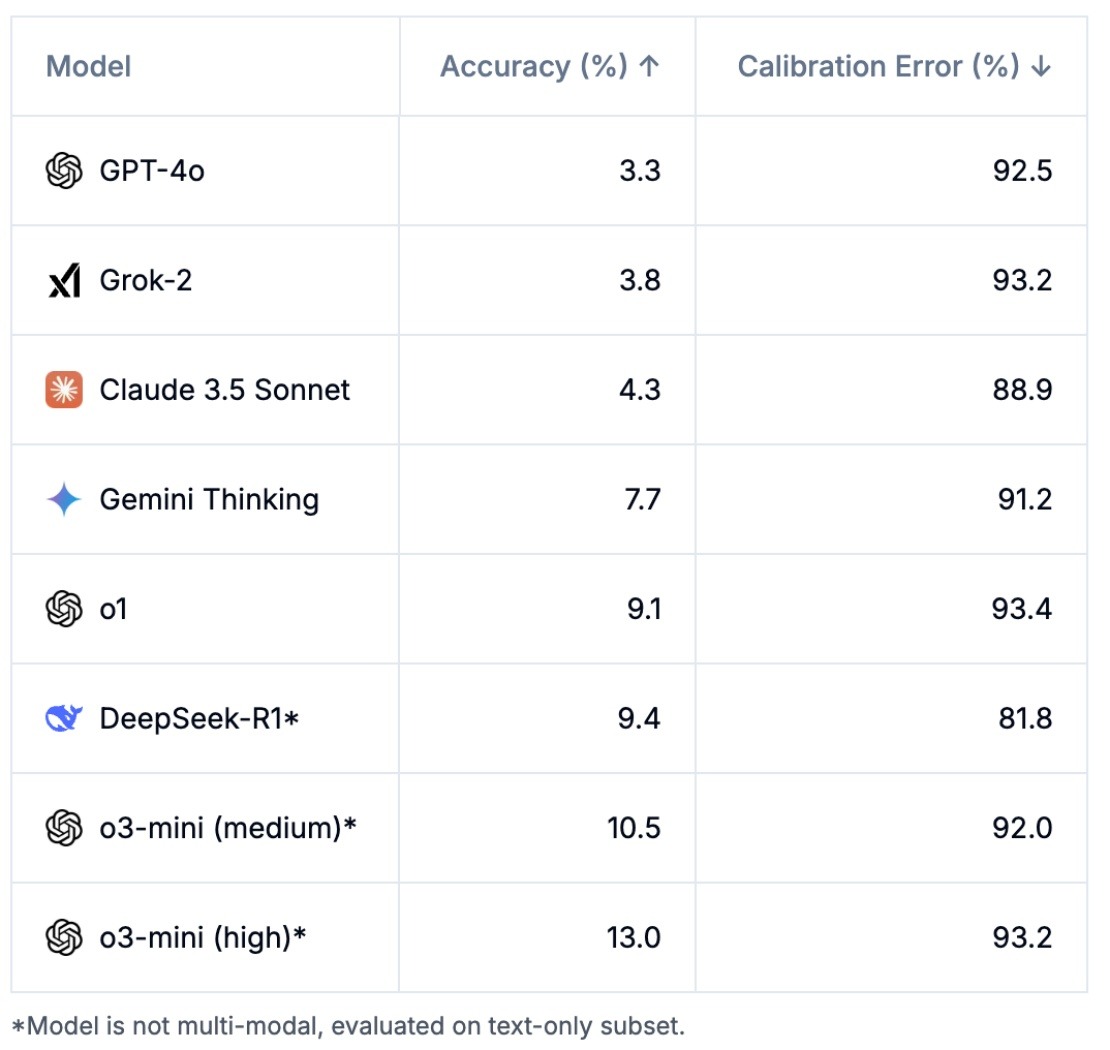
With the latest state-of-the-art models, their scores from "Humanity's Last Exam" are quite low. For example, OpenAI's latest o3-mini (high) only achieved a 13% accuracy rate, while the Chinese open-source model DeepSeek-R1, which recently shocked the Western world, scored just 9.4% accuracy rate.
What Does "Humanity's Last Exam" Test For?
According to the publicly available information on Hugging Face, the dataset for "Humanity's Last Exam" contains 3,000 questions. Here is the breakdown: math dominate (42%), followed by physics (11%), biology and medicine (11%), computer science and AI (9%), and humanities and social sciences (8%). Humanities enthusiasts will find a wide range of topics, including history, linguistics, philosophy, literature, economics, finance, law, classics, cultural studies, religious studies, management, anthropology, archaeology, psychology, political science, education, and sociology.
To prevent the questions from being leaked and used for model training, most of the dataset is kept private and only used during model testing. However, they have released some sample questions.
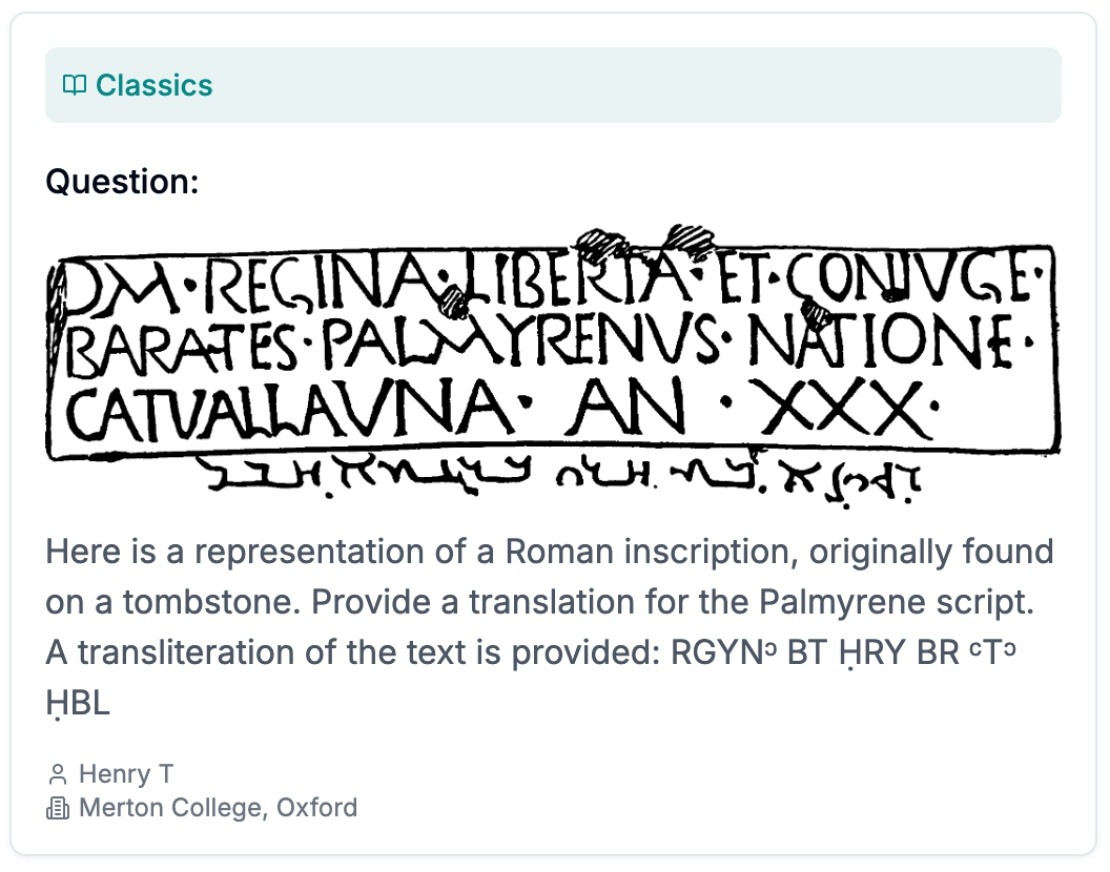
For example, in classics, there's a question about translating Roman inscriptions. In ecology, there's a question about how many pairs of tendons are supported by a hummingbird's sesamoid bone. In linguistics, there's a question about Hebrew Bible studies and ancient Hebrew pronunciation. And for trivia, there's a seemingly easy question: In Greek mythology, who was Jason's maternal great-grandfather?
Hmm. Never mind who Jason is, but deducing family relationships might not be easy for AI either. After all, I struggle with it every year during family gatherings.
Even with the questions kept private and the collective wisdom of many interdisciplinary scholars, humanity's defense might be like the three walls on the island in "Attack on Titan," eventually breached by giants.

Want to join the Survey Corps? (Source: Attack on Titan)
Just about a week ago, OpenAI, in response to the threat of DeepSeek, showcased its leading edge in AI by unveiling the research AI agent Deep Research, which immediately achieved a 26.6% accuracy rate on "Humanity's Last Exam." Since Deep Research, which requires a $200 monthly subscription, uses the yet-to-be-released o3 model, it's clear that the full version of o3 is more than twice as advanced as o3-mini (high).
However, Humanity’s Last Exam has already issued a caveat: “Given the rapid pace of AI development, it is plausible that models could exceed 50% accuracy on HLE by the end of 2025.” We’re only two months into 2025, and AI has already exceeded 26% accuracy. What’s next? The outlook isn’t exactly reassuring. Will there be an even more “Last” Humanity’s Last Exam in the future? It’s a bit like saving a file and naming it final—only to inevitably end up with final_1, final_2, final_3, and so on. Let’s hope humanity keeps pushing forward, holding on to the Homo sapiens title a little longer.


