Since the debut of Sora, the new video-focused generative AI model has not only been used for showcasing military hardware through dazzling videos, but has also sparked intense discussions on OpenAI's ambitions to build a supposed world simulators, as mentioned in their own technical report. OpenAI stated,"One of our core aspirations at OpenAI is to develop algorithms and techniques that endow computers with an understanding of our world"; "Generative models are one of the most promising approaches towards this goal."
This statement becomes particularly intriguing when juxtaposed with a paper they published in 2016, discussing generative models for processing three-dimensional physical spaces— "One of OpenAI's core aspirations is to develop algorithms and technologies that enable computers to understand our world," and "Generative models are one of the most promising approaches to achieving this goal."
It appears that the Sora model is OpenAI's response to the question they posed eight years ago.
However, many are not convinced by this response. Following the release of numerous videos generated by the Sora AI model, critics have pointed out physical inaccuracies, and even AI research luminaries like Yann LeCun have directly stated that generative models are a dead end for building world models.
Why are world models, or simulators as OpenAI refers to them, so important in the field of AI? And why is Sora, despite being "so advanced" that it leaves other video generation AIs like Pika and Runway far behind, still viewed with such skepticism?
World Models as the Holy Grail of AGI
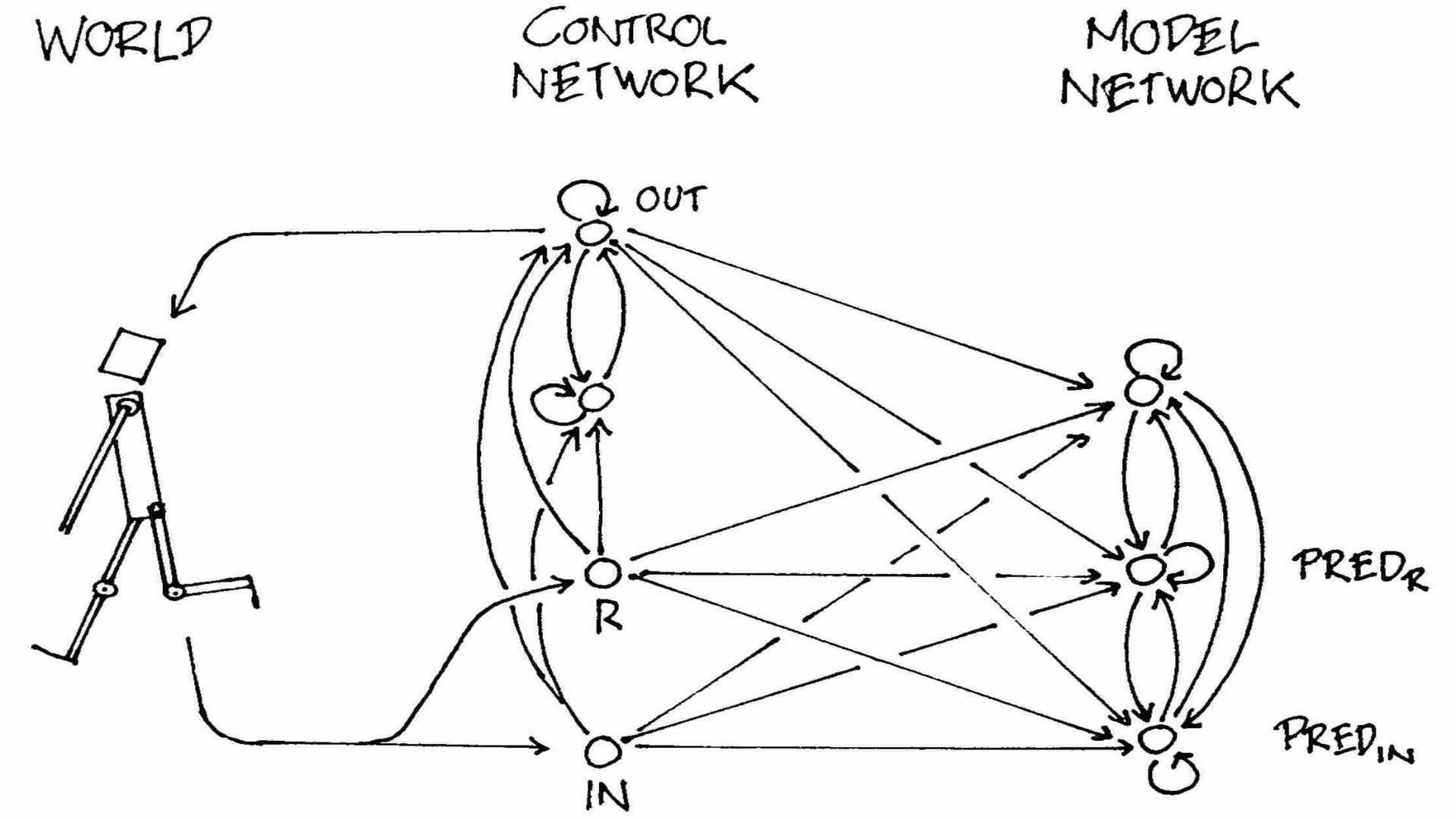
The discussion around world models is best known from a paper by David Ha and Jürgen Schmidhuber titled "Recurrent World Models Facilitate Policy Evolution," which focuses on AI's reinforcement learning. They introduced a fascinating concept: Can intelligent agents learn within their own dreams?
Dreams serve as a metaphor for world models. When AI can "perfectly" learn through training within its simulated environment or world model, it can then apply the decisions made in this model back to the real world—perfection here includes mastery over physics laws.
Imagine if we could repeatedly experiment within a world model to find the best solutions, including counterfactual reasoning of "what if" scenarios. Human errors in the real world would be eliminated, saving an astonishing amount of money and time. We would no longer make wrong votes, love the wrong people, mess up career planning, and what about... life itself? It sounds like a hard science fiction version of Adam Sandler's "Click." This is precisely the moment when artificial intelligence masters world models and achieves AGI.
The reason world models are an unavoidable hurdle on the path to AGI is that current large language models, like GPT, rely on massive training data to deduce statistical correlations and lack the ability to actively deduce new causal scenarios. They can only reason about the data they have seen. Therefore, if language models are to transform and establish a world model that can be used to understand the surrounding environment, causal deduction (especially counterfactual reasoning) is a fundamental element. Achieving this would unlock the next step of self-doubt and self-exploration, akin to humans.
This is why when Sora was introduced with the term "world simulator," it drew fire from AI scientists— did OpenAI speak too soon?
Sora's Secret to Becoming a Master Chef
So, is Sora a world model? This brings us to the core technology of Sora, what OpenAI calls "spacetime patches."
In the past, when AI processed and recognized images, it would divide them into a series of "patches"; in language models, this is similar to using "words" when processing text data. However, the complexity of images and videos far exceeds that of text, so this patch-based method encounters limitations when dealing with fixed-size and aspect ratio images because it requires extensive pre-processing of the images, such as cropping or scaling, leading to a decline in quality—classic tragedies like the "Will Smith eating spaghetti" AI video challenge.
The Sora generative AI model solves this problem by treating the entire image as a sequence of patches, maintaining the original aspect ratio and resolution of the image. The advantage of this approach is that it allows the AI model to learn from visual data that is closer to the real world, greatly improving the quality and accuracy of the generated content.
Just like a chef using fresh ingredients instead of pre-packaged or frozen vegetables and processed meats; when the chef ensures that each ingredient retains its original characteristics and flavor, the resulting dish is naturally more delicious.
Spacetime patches allow for detailed and flexible processing of images, laying the groundwork for more accurate physical simulations and complex features like 3D consistency. This means the Sora generative AI can not only generate extremely realistic images but also ensure that these images follow the physical rules of the real world—at least, they "appear" to.
Potential Limitations of Generative Models as World Models
The videos generated by the Sora generative AI look incredibly lifelike, but many have pointed out physical errors. For example, in a generated video of human archaeology, chairs appear out of nowhere and float in the air unaffected by gravity; in a video of a grandmother blowing out birthday candles, the candle flames remain still; in an ant tunnel video, the ants have only four legs instead of the correct six.
Despite OpenAI's own admission in their technical report of limitations with complex physics, many believe they downplayed these issues. This touches on the fundamental debate over the direction of world models: generative models versus predictive models.
The Sora generative AI combines diffusion models and Transformer models, the latter used to identify and find the relevant spacetime patches in context. Some argue that although Transformer models can manipulate natural language to a certain extent (the best case being ChatGPT), natural language cannot precisely express physics laws, hence the "globally reasonable, locally absurd" situations often seen in Sora videos. This also shows that Transformer models, while capable of learning local context, cannot learn global context. This is the limitation of "probability-based" world models.
That's why Yann LeCun says, "The generation of mostly realistic-looking videos from prompts *does not* indicate that a system understands the physical world.Generation is very different from causal prediction from a world model.The space of plausible videos is very large, and a video generation system merely needs to produce *one* sample to succeed." This means that the "strike zone" for lifelike images is wide, and it's easy for Sora's creations to meet the general public's expectations of images.
Moreover, some point out that since it's unclear how different Sora's videos are from its training data, it's difficult to ascertain the Sora AI model's true capabilities.
Is There a Chance for Predictive Models?
If Sora is a dead end, what is the way forward?
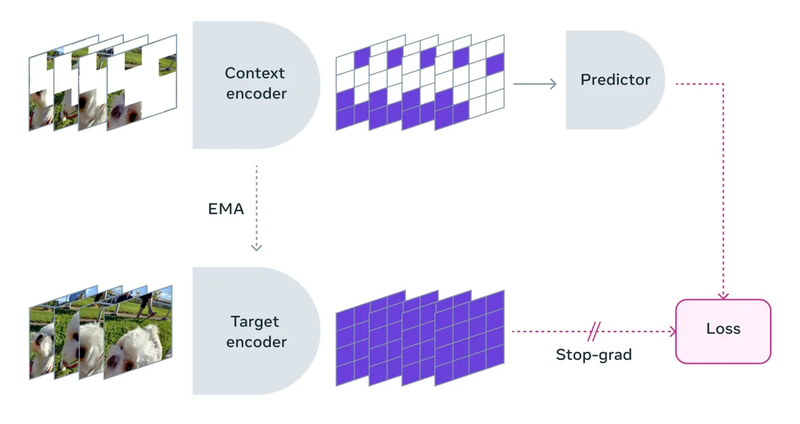
Yann LeCun believes it's V-JEPA (Joint Embedding Predictive Architecture, with V for Video), a non-generative predictive model that allows AI to understand the world by predicting missing or obscured parts in videos.
Researchers exposed the V-JEPA model to a series of videos with large areas obscured, challenging the predictor to fill in the missing parts within the context of only a small portion of the video content. It's important to note that the filling is not actual pixels but abstract descriptions in the representation space (as shown below).
If generative models like Sora are "filling in the corresponding real-world colors" on a blank coloring book, V-JEPA is predicting "what color should be" in the blank spaces.
In Meta's report, V-JEPA is likened to human infants: infants learn about the world by observing their surroundings, intuitively understanding that objects that rise must come down, without needing to spend hours reading books to reach this conclusion (as Sora's training method would).
Although V-JEPA's theoretical potential is shown in Meta's report, we have yet to see its results, making it difficult to judge the winner of this world model Holy Grail battle. However, Meta's release of the V-JEPA model under a CC BY-NC license to promote the development of the AI field does evoke déjà vu: the open Android versus closed iOS debate in the mobile industry years ago. Ironically, many believe that OpenAI has betrayed its original intention to benefit all of humanity, becoming one of the least open-source AI companies today, prompting Meta, IBM, and others to form the AI Alliance to counteract, with members including Hugging Face, Stability AI, Uber, and more.
In the end, the focus of this Holy Grail battle may not be on who wins, but on how these technologies are used to advance human society. This also reveals the tech giants' visions for the future: will it be developed behind closed doors relying on scale and massive data training, or will it be through sharing to foster innovation? Which side can safely develop artificial intelligence to promote the well-being of all humanity, rather than creating a dystopian future? This is a topic we should continue to think about and pay attention to.