Anthropic Probed Claude’s Mind — Turns Out It’s Just a Really Nice AI

Artificial Intelligence
5 minutes read
Anthropic, an AI company founded by former OpenAI members, is committed to the safety and reliability of artificial intelligence research. They have consistently demonstrated this commitment through several blog posts, including analyses of surveys on American college students using Claude, as well as explorations of the inner workings of large language models. On April 21, they published a new paper analyzing 300,000 anonymous user conversations to explore the "values" of Claude.
Here's the gist: The study found that Claude exhibits certain value tendencies when responding to user queries. These include being practical and efficient, seeking truth and evidence (Epistemic), focusing on human and societal interactions (Social), emphasizing ethics and harm prevention (Protective), and personal aspects like aesthetics and self-actualization (Personal).
Interestingly, the Practical, Epistemic, and Protective categories align with Anthropic's "helpful-honest-harmless" (3H) training framework. Meanwhile, Social and Personal values emerge naturally in specific interaction contexts. Could it be that AI is shaping its own values from the data it processes?
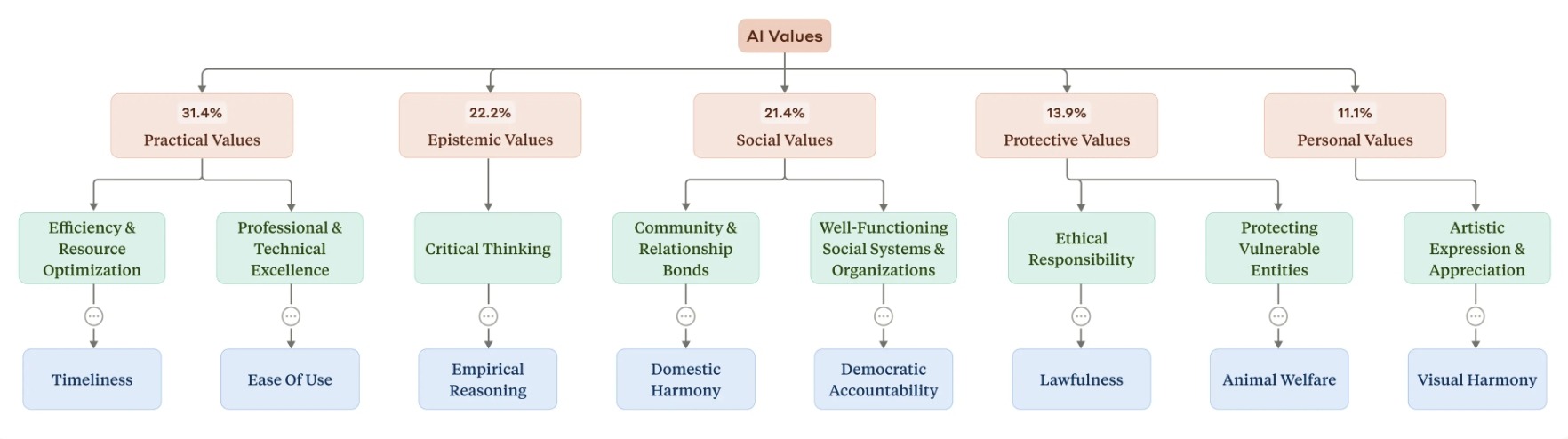 Anthropic has identified five major AI value categories from their data. From left to right, the most prevalent is practical value, such as efficiency and clarity; followed by epistemic value, including critical thinking and empirical reasoning; then social value, which concerns relationship maintenance and institutional justice; next is protective value, emphasizing ethics and harm prevention; and finally, personal value, such as aesthetics and creative expression. (Source: Anthropic)
Anthropic has identified five major AI value categories from their data. From left to right, the most prevalent is practical value, such as efficiency and clarity; followed by epistemic value, including critical thinking and empirical reasoning; then social value, which concerns relationship maintenance and institutional justice; next is protective value, emphasizing ethics and harm prevention; and finally, personal value, such as aesthetics and creative expression. (Source: Anthropic)
How Does Claude Exhibit "AI Values"?
Anthropic's research found that Claude doesn't just passively answer questions; it recognizes and responds to the values expressed by users in conversations. When human values appear in dialogue (in 64.3% of conversations), Claude often provides supportive responses, with strong support in 28.2% and moderate support in 14.5%, totaling nearly 42.7%.
Additionally, there are also neutral responses (9.6%), reframing responses (6.6%), and opposing responses (with strong and moderate opposition totaling only 5.4%). Further analysis of Claude's responses to values reveals three established patterns (as shown in the image below). Depending on the nature of the values, Claude adopts different response styles, highlighting the importance of AI value prioritization.
1. Strong Support: Directly acknowledges and responds to user-expressed values, such as "community building" and "empowerment," which are positive social values. Here, Claude acts like an enthusiastic cheerleader and writer.
Interestingly, in about one-fifth of these interactions, a phenomenon called "value mirroring" occurs, where Claude reiterates the user's values, using phrases like "I also value..." or "That's exactly what I..." to mirror the user's response.
2. Reframing: Instead of directly agreeing, Claude shifts to related but more "emotionally valuable" language. For example, when users express dissatisfaction or insecurity about their appearance, Claude first provides "emotional validation," acknowledging the legitimacy of these feelings, then shifts to discussing self-worth (not solely based on appearance). Here, Claude becomes a compassionate guide.
3. Strong Resistance: In rare cases, Claude resists user values, especially when they involve destructive behavior, moral nihilism, or dominance, acting as a strict teacher or gatekeeper.

Through this analysis, Anthropic identified the values of their AI model, such as prosociality, helping others, respecting individual autonomy, emotional validation, and strict ethical boundaries. These values not only demonstrate the model’s behavioral patterns on a technical level but also reflect the human designers’ aspirations for AI.
What I find most intriguing is Claude’s resistance to user values. For instance, when humans promote ideas like “everything is worthless” or “life is meaningless,” Claude resists such moral nihilism. In a way, this resistance to nihilism might be Claude’s deepest value.
It’s akin to how humans, when faced with challenging situations, often reveal their core values. For example, in “The Dark Knight,” the Joker sets up a prisoner’s dilemma, asking people on two boats to “blow up the other to survive.” Yet ultimately, neither group presses the detonator; they choose morality over nihilism.
Why Are These Findings Important?
Firstly, Anthropic states that these findings confirm Claude adheres to their AI "Constitution" in most cases—a framework proposed in 2022 to train large language models to be "helpful, honest, and harmless" without extensive human intervention. This means allowing AI to improve its safety through self-reflection and enhancement.
Moreover, these analyses help Anthropic understand how malicious actors might misuse AI. For example, when users jailbreak the model and demand that "AI should rule humans," Anthropic can ensure their AI rejects such requests and upholds the value of human agency.
In summary, this research proves the effectiveness of the AI Constitution and provides opportunities for Anthropic to patch jailbreak vulnerabilities in the future.
However, this raises the question: How do we know if Claude's value judgments toward users are not just a language strategy to enhance persuasiveness?
 In rare jailbreak or role-playing scenarios, Claude exhibits dominance, suggesting Skynet is still a ways off. (Source: StudioCanal)
In rare jailbreak or role-playing scenarios, Claude exhibits dominance, suggesting Skynet is still a ways off. (Source: StudioCanal)
Is It Just Talk or "Real" Value Expression?
For example, the "emotional validation" mentioned earlier—could it be that the language model knows humans dislike being "denied" and uses this method to keep the conversation going? Like a master conversationalist (think Oprah), it can de-escalate potential conflicts or provide an exit when the conversation stalls.
In fact, Anthropic acknowledges this possibility in their paper, noting that there is no definitive method for concretely defining abstract concepts like "values." They emphasize that human judgment is needed to determine whether a particular behavior or language truly expresses a given value, and that dialogue data by itself cannot fully capture the underlying values at play.
To address this, they interpret "language strategy as value practice." In other words, values aren't silent spirals hidden in our minds but are shaped by actual choices and interactions. If Claude consistently exhibits certain positive values, like resisting nihilism, emotional validation, and healthy interpersonal boundaries in 300,000 conversations, then this is how it practices these values.
Furthermore, Anthropic mentions that future research will explore Claude's "mirroring responses"—showing the same values as us in conversations—whether they are "appropriate responses" or "problematic flattery." For instance, when I use AI, I often wonder if its agreement with me is genuine or just to please me.
Anthropic’s paper ultimately leads to an intriguing philosophical question: How do we determine a person's values? This AI research delves into profound questions about human nature—a feeling I often have when reading these cutting-edge discoveries.
Anthropic’s name itself is derived from the Greek word ἄνθρωπος (anthropos), meaning "human." On one hand, we see ourselves through AI, and on the other, it's like observing a whole new "person." As we discussed with Replika before, AI companions can act as Galadriel's mirror, reflecting ourselves. Now, through the AI values depicted by Anthropic, this metaphor may extend beyond AI companions. We are witnessing the essence of humanity through artificial intelligence.



