Have you ever wondered how an AI model “thinks” while chatting with you? Traditionally, people only knew that large language models (LLMs) like this one generate text by predicting probabilities, but the inner workings remained a mystery. A while ago, on March 27, Anthropic released two studies that unveiled Claude’s "decision-making" process using a technique akin to giving the AI an MRI. (The research version used was Claude 3.5 Haiku, hereafter referred to as Claude.) One surprising finding is that AI can actually plan ahead, offering new insights into how these models work.
How Did They Open and Peek Inside the AI "Brain"?
1. Circuit Tracing
As we discussed in our previous article "Can AI Move from Rote Learning to Understanding?", current LLMs use the Transformer architecture, operating through a "self-attention mechanism." With this in mind, the Anthropic team wanted to know which attention modules or neurons play a crucial role when the model generates content. It's like entering a new hotel room and figuring out which switch controls which smart device or light bulb, a process central to AI interpretability.
Using this technique, Anthropic discovered that when Claude writes poetry, certain modules decide on the rhyming word at the end of a line before the entire sentence is generated. These modules are activated early within the model, guiding the subsequent generation direction. This finding contradicts the research team's assumption that Claude generates word by word, deciding on the rhyme last.
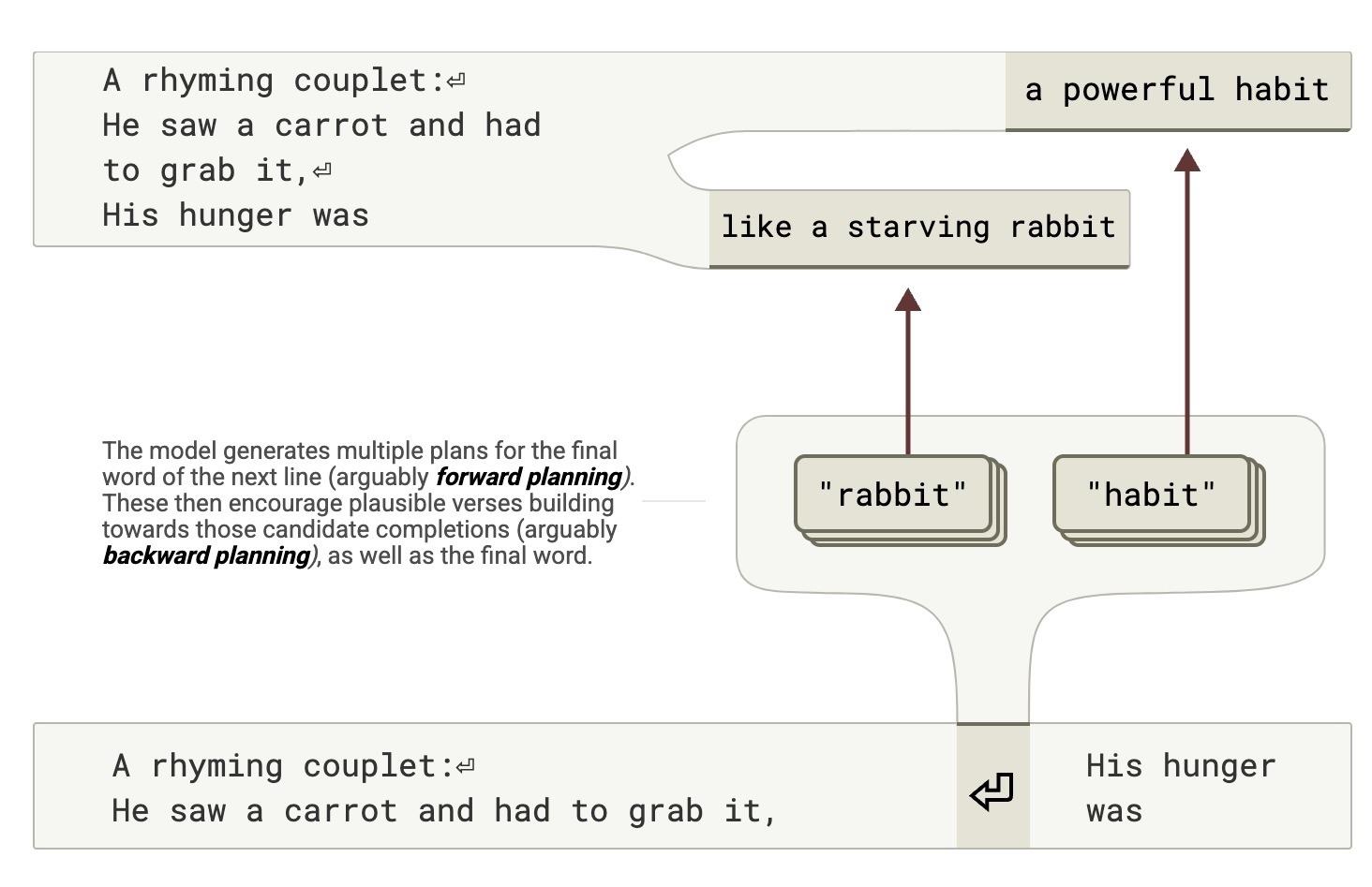 Anthropic found that when the language model generates poetry, it predicts the rhyming word at the end of a sentence first. For instance, when writing "His hunger was…", the model had already chosen potential rhyming words (like rabbit or habit) at the end of the previous line "He saw a carrot and had to grab it." (Source: Anthropic)
Anthropic found that when the language model generates poetry, it predicts the rhyming word at the end of a sentence first. For instance, when writing "His hunger was…", the model had already chosen potential rhyming words (like rabbit or habit) at the end of the previous line "He saw a carrot and had to grab it." (Source: Anthropic)
2. Functional Substitution
With an initial "circuit map," the research team wanted to go further—not just knowing which button controls which light, but also replacing some bulbs with transparent ones to see how they light up. This concept, known as functional substitution, is a key aspect of AI interpretability.
Anthropic designed a set of "observable modules" that can replace the original black-box modules without disrupting the model's overall performance. These substitutes are like replacing the wires inside a wall with transparent ones, letting you see where the current flows and how it reaches its destination, all without affecting the room's lighting.
At one point, they had Claude solve a math problem and discovered that the model retains information across intermediate steps—much like how humans keep track of numbers when calculating mentally. While the researchers did not use the term "stacked memory" in their study, this phenomenon can be described as a kind of stacked memory: the model accumulates and reuses information step by step during multi-stage reasoning, similar to how people use working memory. Previously, scientists could only speculate about the existence of this internal memory structure, but now they can finally see it manifesting in the AI "brain."

The image shows that, instead of following a single processing path, the language model simultaneously activates two internal pathways: one that estimates the sum range (e.g., 30–70 plus 50–60), and another that computes the digit sum (e.g., 6 plus 9 equals 5). The two pathways converge and compare their results, outputting the answer 95 when they match. (Source: Anthropic)
3. Attribution Graph
Once all the transparent wires are in place, the research team creates a complete map of the room's electrical flow. This map visualizes which switch connects to which wire, and which wire lights up which bulb within these complex relationships—ultimately enhancing AI interpretability.
Anthropic transformed the information flow between modules during model output into a graph, with each connection assigned a value representing how much that transmission affects the final output. For the first time, the model's internal "responsibility allocation" from input to output is concretely depicted.
At one point, to illustrate this phenomenon, imagine Claude answering a geography question such as “What country is Sarajevo the capital of?” If the model gave an incorrect answer—an example of what we commonly call an AI hallucination—researchers could use the attribution graph to trace the cause of this hallucination not to random generation, but to certain modules that were overly active in “creating place names,” even pinpointing which layers of “attention” were problematic.
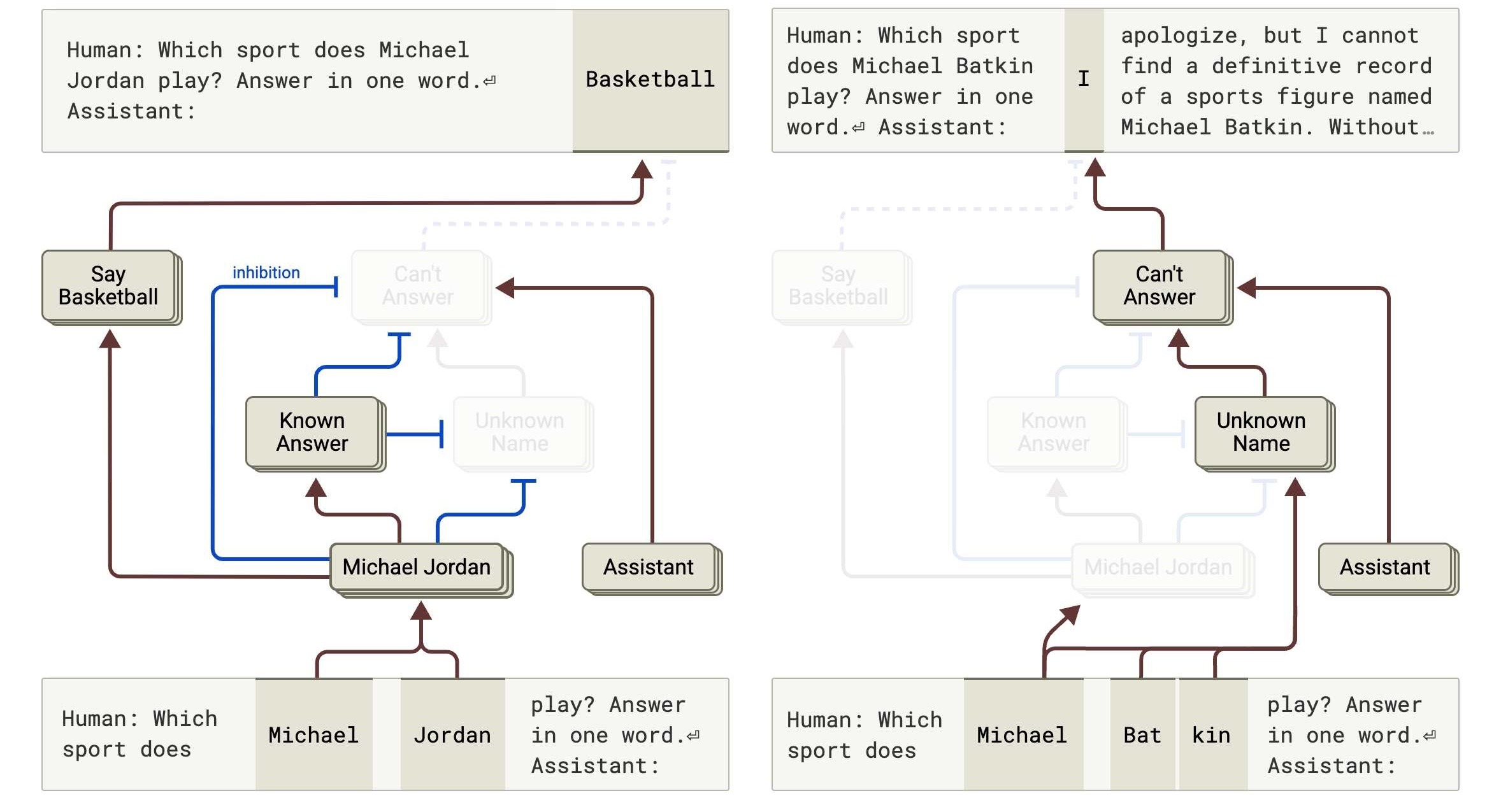
When asked "What sport does Michael Jordan play?", Claude activates the "known answer module," producing "Basketball." But when the fictional character "Michael Batkin" is used, the model shifts to the "unknown name" module, ultimately outputting "unable to answer." Through the attribution graph, researchers can mark the involvement of different modules, the direction of information flow, and even see which modules suppress incorrect paths, making both errors and correct answers traceable. (Source: Anthropic)
In other words, they not only know the model made a mistake but also how it made the mistake. This ability to trace and correct errors gives us the first opportunity to address AI hallucinations effectively.
AI Models Can Plan Ahead, Achieving Multilingual Consensus
As mentioned earlier, the team observed that when Claude writes poetry, it plans the rhyme first and then fills in the middle text. This discovery's significance extends far beyond poetry. They also found that when the model answers reasoning questions, it forms a "conclusion outline" first and then constructs the reasoning steps. It's like someone having a stance and then finding reasons to support it—sounds familiar, right?
However, this discovery also reveals the challenge of alignment tasks. It suggests that the model might pre-assume "this is the answer humans want" and then fill in the reasoning or text. The model might appear aligned with human values (producing reasonable arguments) on the surface, but it may have only learned how to make its output seem aligned with human expectations, rather than genuinely internalizing these values. (Hmm, sounds a lot like humans…)
Another intriguing finding relates to whether AI can truly understand semantics. Anthropic discovered that the model's internal "semantic representations" are aligned across different languages.
For example, when you input the words "dog," "chien," and "狗" in English, French, and Chinese, respectively, the model processes them by converting them into nearly overlapping neural representations. This indicates that although the large language model is trained on multilingual data, it spontaneously forms a language-neutral semantic space, categorizing different language words with the same meaning in this space.
In other words, AI might not just be "translating between languages" but finding commonalities among multiple languages at a deeper semantic level (neutral space).
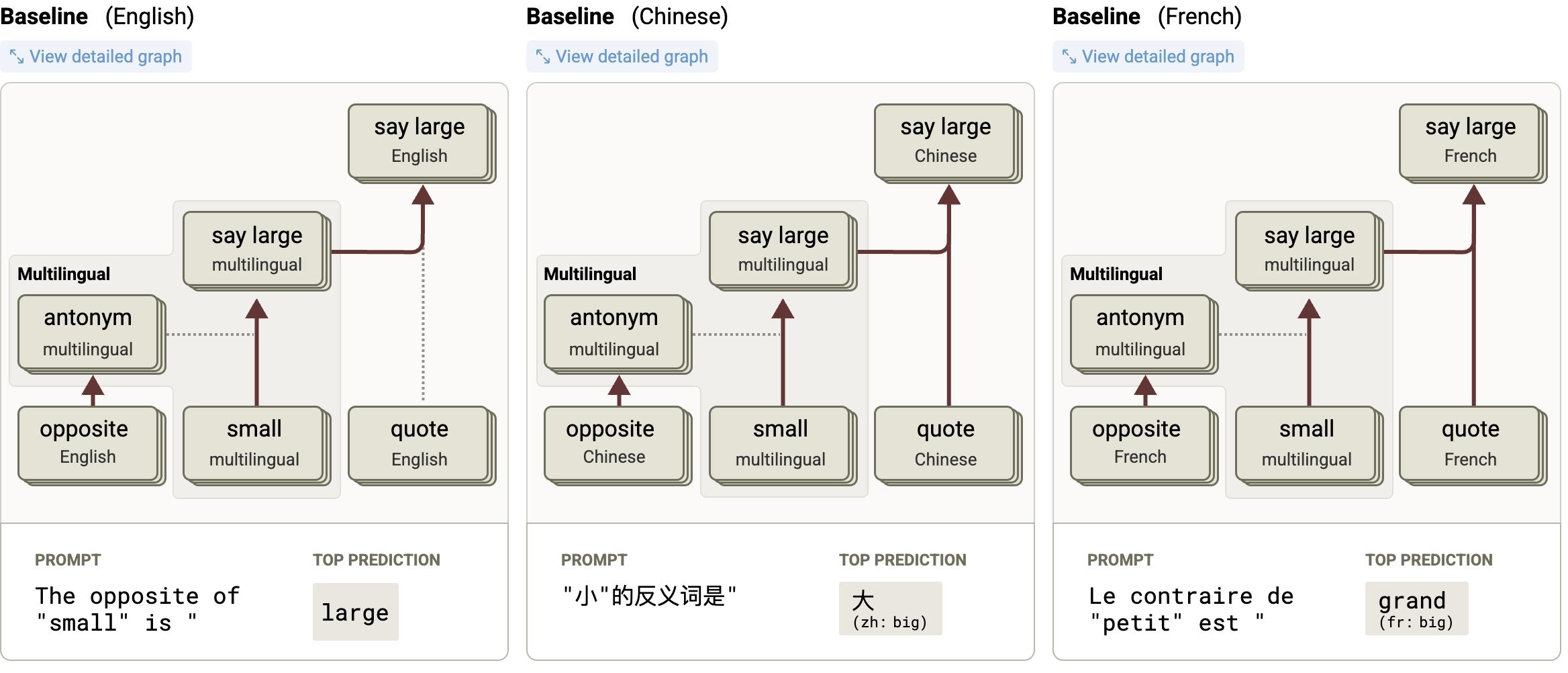 When you ask “What’s the opposite of small?” in English, “小的反義詞是什麼?” in Chinese, or “Le contraire de petit est” in French, the model processes the concept of “small” through the same semantic module before outputting “large,” “大,” or “grand” through the respective language modules. This demonstrates that the model has spontaneously formed a shared semantic space across different languages. (Source: Anthropic)
When you ask “What’s the opposite of small?” in English, “小的反義詞是什麼?” in Chinese, or “Le contraire de petit est” in French, the model processes the concept of “small” through the same semantic module before outputting “large,” “大,” or “grand” through the respective language modules. This demonstrates that the model has spontaneously formed a shared semantic space across different languages. (Source: Anthropic)
Anthropic's findings not only identify the cause of AI hallucinations—not as random, but due to specific, overly active areas within the model—but also reveal the logic behind the internal operations of large language models, which in some respects are quite similar to humans. This represents a significant breakthrough in AI interpretability. However, this "AI MRI" approach still has its limitations.
First, it is extremely time-consuming and labor-intensive. The research team admits that completing a single analysis of an AI generation requires days or even weeks of computation and manpower, all conducted in a costly GPU environment. The results also depend heavily on expert interpretation. Moreover, this approach functions more as a "case study" for specific scenarios, unable to scan all functional modules and behavioral patterns in the model at once—which further exacerbates the challenges of time and effort.
Now, for the first time, we can understand a little more about how this "artificial brain" operates, discovering that its workings are more complex and profound than we imagined, reminiscent of what biologist Lyall Watson said when discussing why understanding human consciousness is difficult:
If the brain were simple enough for us to understand, we would be too simple to understand it.
If AI—created by humans and not yet as complex as our own brains—is already difficult for us to understand, how many secrets must the unparalleled design of the human brain contain? And who, if anyone, designed it?



