DeepSeek's emergence has clearly accelerated the development pace for competing AI companies. Anthropic recently launched Claude 3.7 Sonnet, touted as the "world's first hybrid reasoning model." In simple terms, users can choose between "Quick Response" (Normal) or "Extended." The latter is the major update, allowing the AI to showcase its thought process, self-reflect on questions, and even play Pokémon Red, where it managed to beat the third gym to demonstrate its AI problem-solving capability.
Claude 3.7 Sonnet playing Pokémon Red! (Source: Anthropic)
What is a Hybrid Reasoning Model?
Let's dive deeper into what a hybrid reasoning model is. According to the official website, it's akin to how our brains should simultaneously possess deep thinking and quick response capabilities, rather than separating them.
In standard mode, Claude 3.7 Sonnet acts like the "fast thinking" part of our brain, an upgraded version of Claude 3.5 Sonnet. In extended mode, it mirrors our "slow thinking," allowing for self-reflection and enhanced problem-solving. So, if your question is complex and requires reasoning, opt for the extended mode, which is perfect for AI reasoning tasks.
For general users, choosing "Extended" satisfies complex problem needs. (Source: Anthropic)
If you're using Claude via API, you might feel this upgrade even more. You can control the "budget" of thinking: instruct Claude 3.7 Sonnet not to exceed a certain number of tokens, with a maximum limit of 128K. This allows users to balance speed (cost) and response quality, adjusting as needed.
This is Anthropic's response to the AI model reasoning chain battle sparked by Deepseek. For instance, Sam Altman recently hinted that OpenAI's upcoming GPT-4.5 will be their last non-reasoning chain model.
What Else is New in This Update?
Additionally, Claude 3.7 Sonnet can more precisely differentiate user queries, reducing the frequency of refusing to answer questions by 45% compared to previous models. Anthropic also reflected on past AI tests, which often included math or science research topics far removed from everyday use. They have reduced this focus to concentrate more on the LLM's practical problem solving.
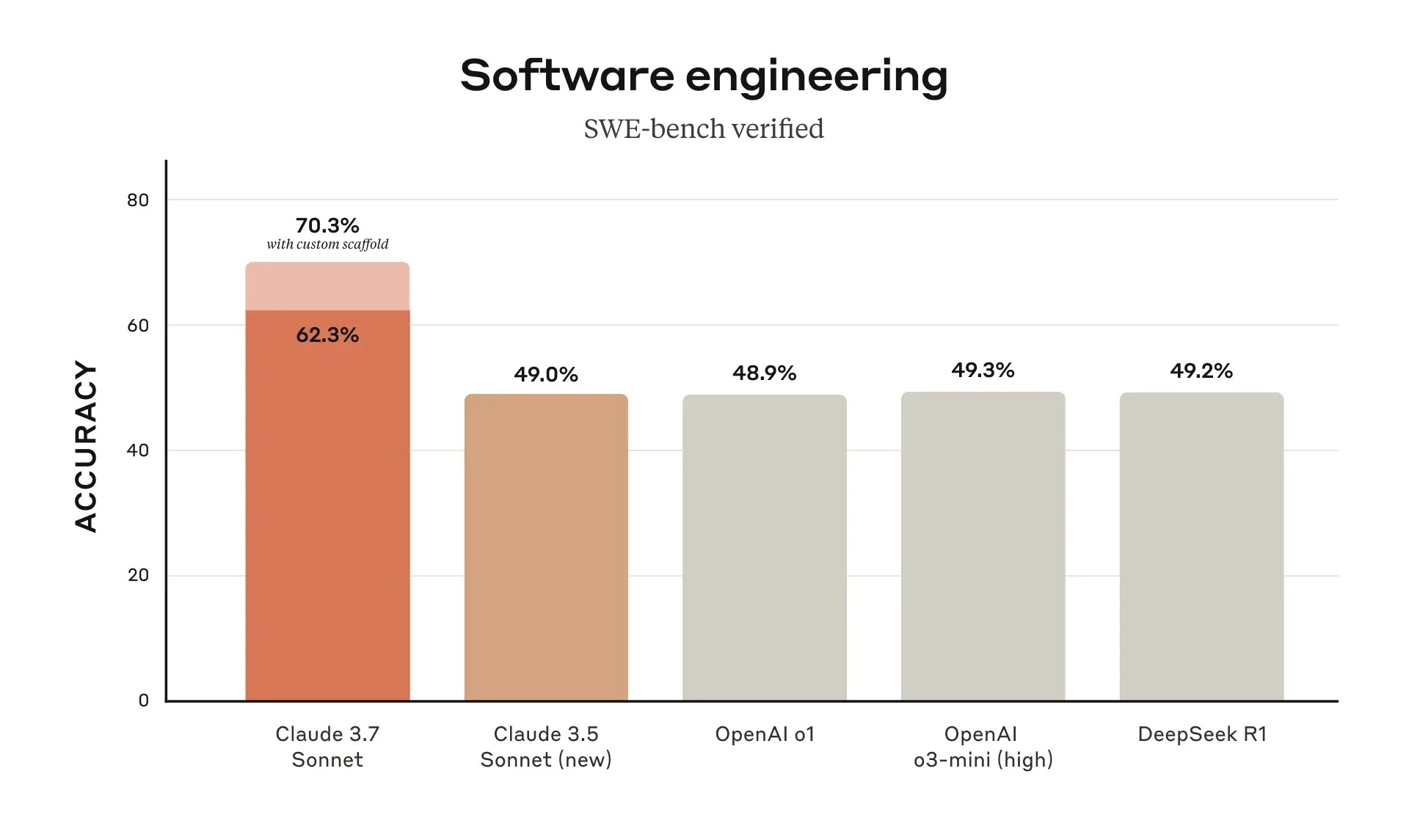
As shown in the two charts released by Anthropic, "Software engineering" demonstrates the AI model's accuracy in the SWE-bench test—designed to assess if AI can think and solve problems like professional engineers. Claude 3.7 Sonnet performed best, achieving 70.3% accuracy (when using custom auxiliary tools, like plugins designed for it), and 62.3% without auxiliary tools.
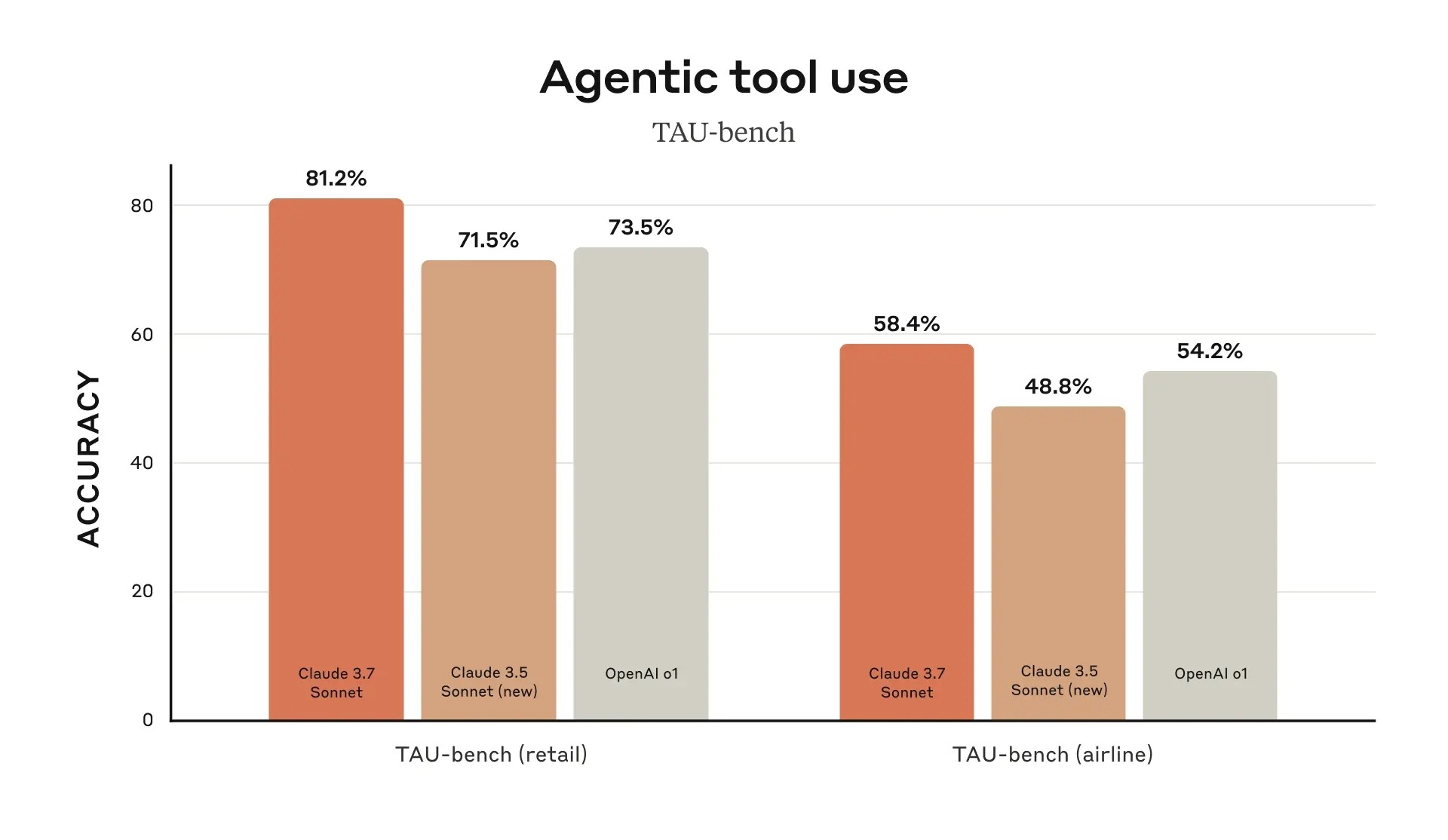
The second chart, "Agentic tool use," shows performance in the TAU-bench test (measuring AI's ability to use external tools to complete tasks). On the left is the retail scenario, testing AI's ability to handle retail-related tasks like product queries, inventory management, and price comparisons. On the right is the airline scenario, testing AI's ability to handle airline-related tasks such as flight queries, booking processes, baggage regulations, and delay handling, which involve complex rules and processes. The chart shows all models perform lower in this area, but Claude 3.7 Sonnet still leads among all contenders.
In this update, Anthropic also introduced a programming tool called Claude Code, which claims to understand users' code libraries and write programs based on natural language commands to simplify workflows. However, this feature is currently in a limited research preview. Lastly, there's a small but significant update: Claude now has a share feature, allowing you to share your conversations with it via a link, a long-awaited addition.
Can Pokémon Games Test AI?
Finally, an interesting tidbit: Anthropic also had Claude 3.7 Sonnet venture into the Game Boy game Pokémon Red to see how far it could progress.
This is reminiscent of when we previously discussed AI companies deploying 1,000 intelligent agents in Minecraft, resulting in the birth of a civilization. Games like Minecraft, with their vast openness and support, have long been training grounds for AI by companies like Microsoft and OpenAI.
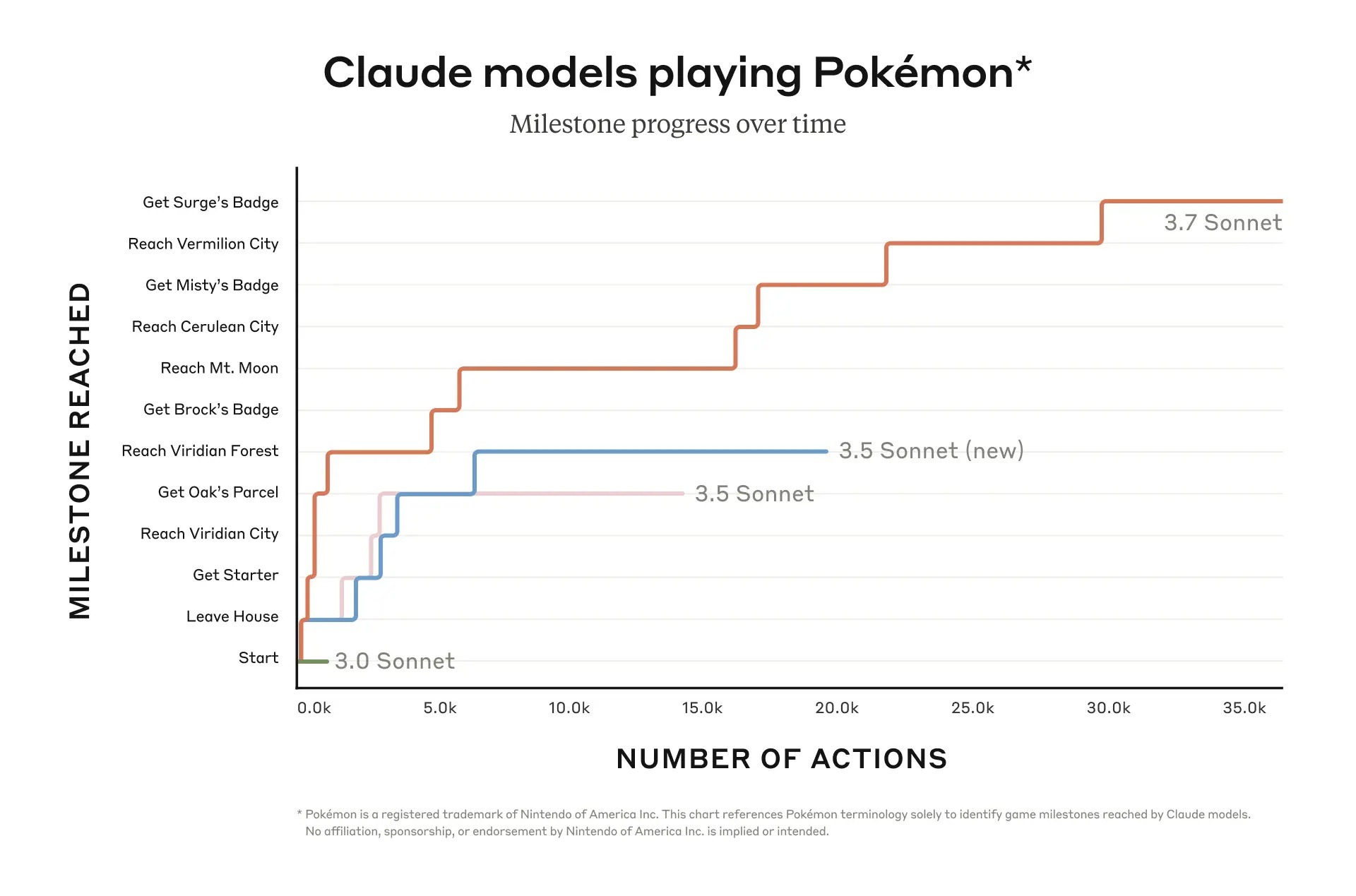
Anthropic's Pokémon Master test specifically had Claude 3.7 Sonnet, under official adjustments, reach the level of defeating Lt. Surge, the Electric-type gym leader in Pokémon Red. The previous 3.5 new version could only reach Viridian Forest (yes, the place where you used to catch Metapods) before stalling. Anthropic attributes this progress to the latest model's extended thinking feature, highlighting its AI problem-solving prowess.
Anthropic has always maintained a steady approach in the AI race—it's not the most eye-catching competitor, and its iterations are relatively slow. This latest update marks its return to the forefront of state-of-the-art models, even drawing attention by having its AI model play Pokémon Red (with the project "Claude Plays Pokémon" streamed on Twitch). However, with OpenAI already announcing that a new generation of models is on the way, one can only wonder how long its leading position will last. Meanwhile, with Claude lacking "DeepSearch" and even basic search capabilities, how will it continue to compete?

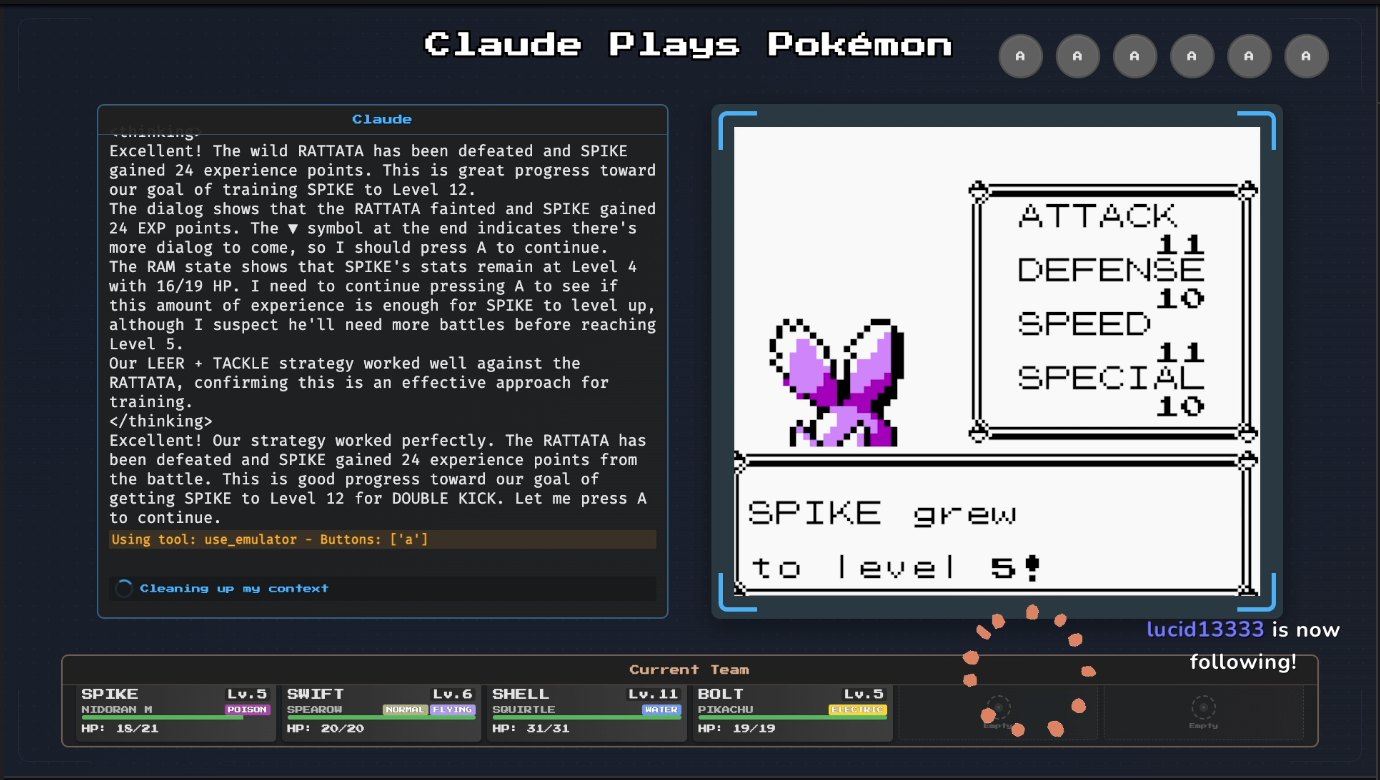 Claude 3.7 Sonnet playing Pokémon Red! (Source: Anthropic)
Claude 3.7 Sonnet playing Pokémon Red! (Source: Anthropic)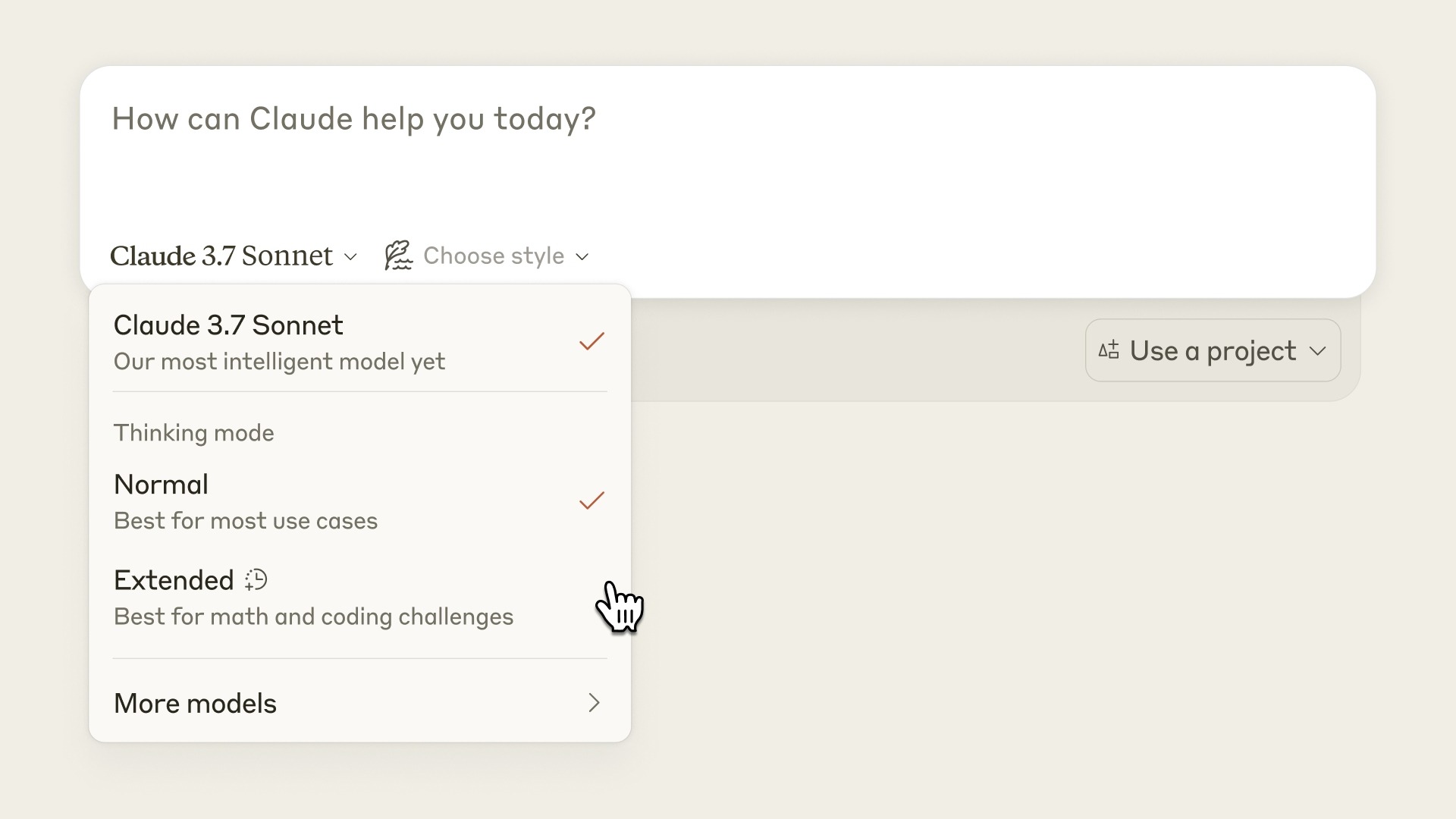 For general users, choosing "Extended" satisfies complex problem needs. (Source: Anthropic)
For general users, choosing "Extended" satisfies complex problem needs. (Source: Anthropic)