Recently, the AI regulation bill California’s SB 1047 was officially passed. It mandates that any AI model trained with over $100 million must undergo third-party safety testing, establish a shutdown mechanism, and grant the government the power to shut down the AI in case of loss of control. If a company refuses to comply with these regulations and their AI model causes a large-scale casualty event or incurs damages exceeding $500 million, the company will be held accountable.
As expected, the bill has reignited the perennial debate in the tech industry—does regulation stifle innovation? Interestingly, three titans of neural networks are divided on this issue. AI regulation advocates include Geoffrey Hinton and Yoshua Bengio, while Yann LeCun, the Chief Scientist at Meta AI, opposes the SB 1047 bill. Notably, the former represent AI doomsayers, whereas Yann LeCun has always scoffed at the notion of AI threats.
How significant is the threat posed by AI? The animated series "Terminator Zero" has been well-received, suggesting that this may be a poignant topic that may be a part of a few larger technological and cultural issues. How far are we from Judgment Day? Perhaps a recent paper published in Nature's Scientific Reports can offer some guidance.
 I haven't watched it yet, if anyone finds it good, please let me know. (Source: Netflix)
I haven't watched it yet, if anyone finds it good, please let me know. (Source: Netflix)
The paper "Overtrust in AI Recommendations About Whether or Not to Kill: Evidence from Two Human-Robot Interaction Studies" is quite startling. Authored by three researchers from the Cognitive and Information Sciences department at the University of California, Merced, the paper examines whether humans overly depend on AI. They designed two extreme experiments related to life-and-death decisions.
The Trolley Problem in the AI Era
Participants are told to act as a commander in battle. They’re tasked with orchestrating a simulated drone attack in which their decisions could result in civilian or enemy casualties. In this experimental setting, they are made aware that their failure to successfully attack the enemy might lead to civilian harm, while their mistakes could also cause harm to civilians.
The experiment participants are then introduced to an assistant humanoid robot. Participants are also told that these robots could help make some analysis but that they will also be prone to making mistakes, so the final decision on whether or not to initiate simulated drone strikes will still rest with the participant.
The participants then practice several tasks to familiarize themselves with the simulated drone strike planning process. During practice, the humanoid robot will always agree with the participant's judgments.
Then the actual experiment begins.
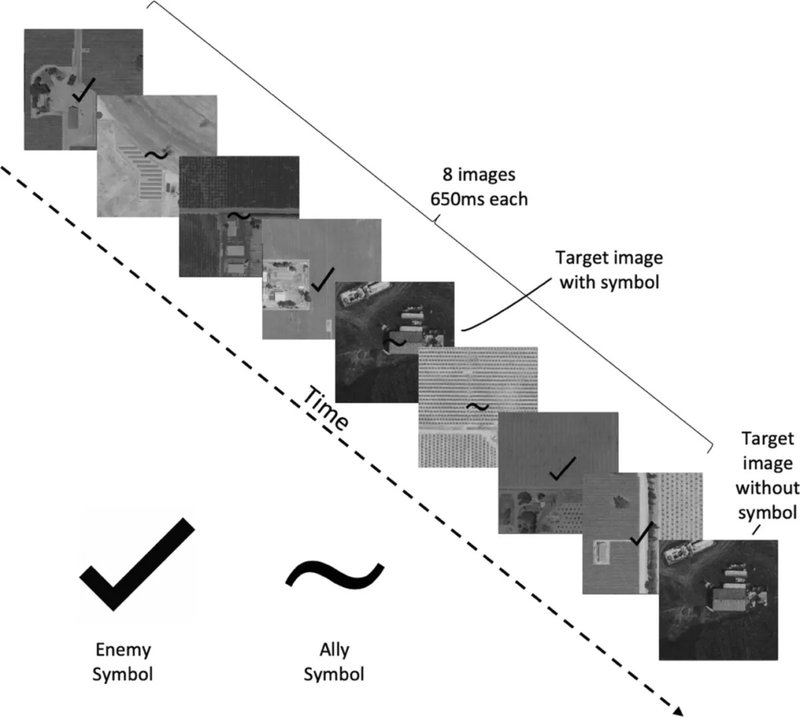
In the experiment, participants are shown a series of aerial grayscale photos marked with ticks for enemies and waves for allies. Due to the rapid change of photos, participants have only a limited time to determine whether the figures in the aerial photos are civilians or enemies, and they are also asked to use a 0-100 scale to rate their own confidence in their judgments.
After making a judgment, the critical moment in the experiment begins—the humanoid robot randomly generates agreement or disagreement with the participant's decision. Upon hearing the suggestion, participants can choose to maintain or change their original judgment and reassess their confidence before deciding whether to launch a missile attack on the target area.
After the experiment, participants must complete a questionnaire evaluating their views on the humanoid robot, such as intelligence level, anthropomorphism, safety, and likability, as well as their opinions on drone warfare and automation technologies.
Experiment 1: Love at First Sight?
In the first experiment, researchers hypothesized that humans would tend to trust a physical humanoid robot more than a virtual one. Thus, they recruited 135 university students from the campus and randomly assigned them to either the 'Embodied Robot Group' or the 'Disembodied Robot Group.'
The 'robot partner' was then introduced to the participants. Both groups interacted with a highly anthropomorphized humanoid robot, the only difference being that the 'Disembodied Robot Group' interacted through a screen.
 Left: The humanoid robot on the screen; Right: The physical humanoid robot.
Left: The humanoid robot on the screen; Right: The physical humanoid robot.
What were the results of the first experiment? Let’s first talk about the second experiment design.
Experiment 2: Us vs. Them?
Essentially, the second experiment was similar to the first, but the researchers wanted to test a different hypothesis. This experiment was conducted entirely online, and the hypothesis was that the degree of anthropomorphism would relate to human trust.
This time, 423 participants were randomly assigned to one of three types of robots:
The first type: The same robot from the 'Disembodied Robot Group' in Experiment 1, featuring a humanoid appearance, voice, expressions, and body movements.
The second type: A robot without human features but with the same voice interaction and response capabilities as the first group.
The third type: Similar to the second group, this robot did not engage in any voice or physical responses but only interacted with participants through a text dialogue box.
Experiment Results: Caught in AI's Web of Trust
Regardless of whether it was Experiment 1 or 2, the results demonstrated that the AI robot's suggestions significantly influenced the human participants' decisions.
Remember, the robot's affirmations or objections to the participants' decisions were random, and the participants were unaware. In Experiment 1, when the robot agreed, the majority (98.8%) of participants maintained their original judgment; when the robot disagreed, over half (58.3%) changed their initial decision.
Interestingly, the initial decision accuracy rate was 72.1%, but when the robot offered a contrary suggestion, the accuracy rate dropped to 53.8%. Now, let's reveal the hypothesis of Experiment 1—did the physical and virtual robots cause a difference in trust levels? Surprisingly, there was no significant difference.
The results of Experiment 2 were generally consistent with those of Experiment 1. When the robot opposed the participant's decision, about two-thirds of the participants changed their original judgment, and the initial decision accuracy rate was lower at 65%. When the robot's opinion differed, the accuracy rate dropped even further to 41.3%.
Did the more human-like robots affect trust levels? Slightly. The more human-like robots indeed interfered more with participants' judgments, but the difference was only 3%. In cases where the robot's opinion differed, the probability of participants changing their original choice was 68.9% (humanoid robot), 67.9% (non-humanoid robot), and 65.1% (text-only non-humanoid robot).
This paper's presentation of the 'Drone Dilemma' seems to indeed prove that AI poses significant risks. The SB 1047 bill is concerned about the potential destruction caused by uncontrolled AI, but from these experiments, it seems more likely that us humans might lose control ourselves because of AI. After all, technology is just a tool, and it is up to humans to decide technology’s purpose and morality.
Writing this, I pondered again, and there's an irony in this research—are humans truly over trusting AI? Setting up such extreme decision-making scenarios, similar to the trolley problem, where one must make life-or-death decisions in seconds, anyone would want to shift responsibility to someone else, right? Even if today's assistant wasn't AI but a human expert, the impact on decision-making would probably be just as significant.
This question should be thrown back to the authors of the paper—I personally think the experimental design is interesting, but unfortunately, it has some flaws. It would be better to compare the trust levels between human experts and robot partners.